
大语言模型增强的关系算子体系与基准测试分析
随着大语言模型的发展,诸多研究通过类似算子的组件将大语言模型集成到关系型数据处理任务中,例如带有语义谓词的过滤器、知识增强的表格插补、数据实体匹配以及复杂的语义查询处理。这些组件在调用大语言模型的同时保留了关系型的输入和输出接口,因此被称为大语言模型增强的关系算子。然而,现有的此类算子存在定义碎片化、实现策略各异以及缺乏全面评估基准等问题。
With the development of large language models, numerous studies integrate these models through operator-like components to enhance relational data processing tasks, such as filters with semantic predicates, knowledge-augmented table imputation, entity matching, and complex semantic query processing. These components invoke large language models while preserving a relational input and output interface, and are thus referred to as large language model-enhanced relational operators. However, existing operators suffer from fragmented definitions, various implementation strategies, and inadequate evaluation benchmarks.
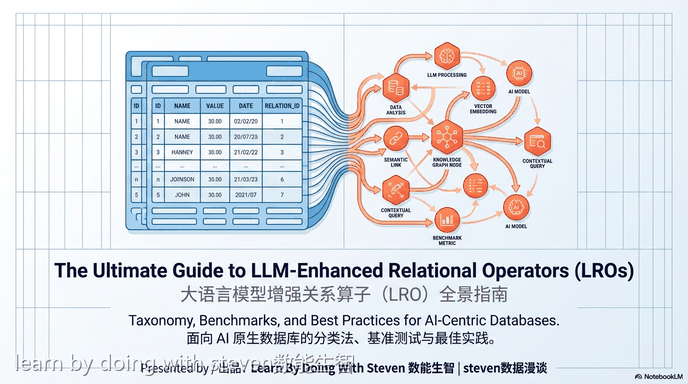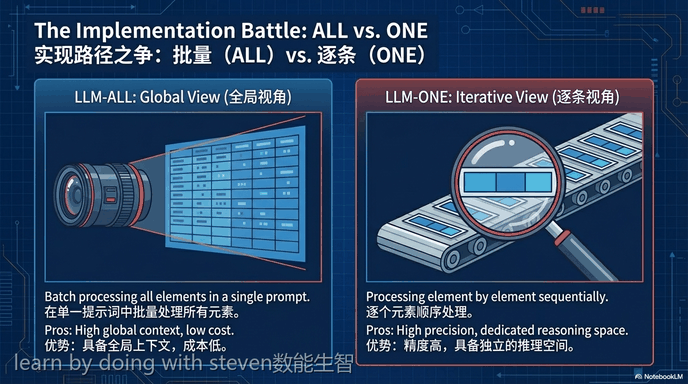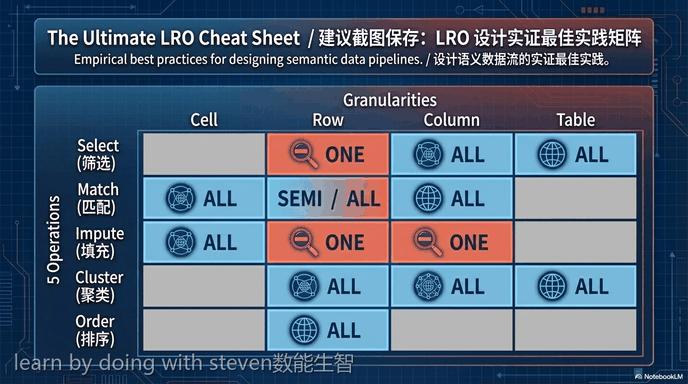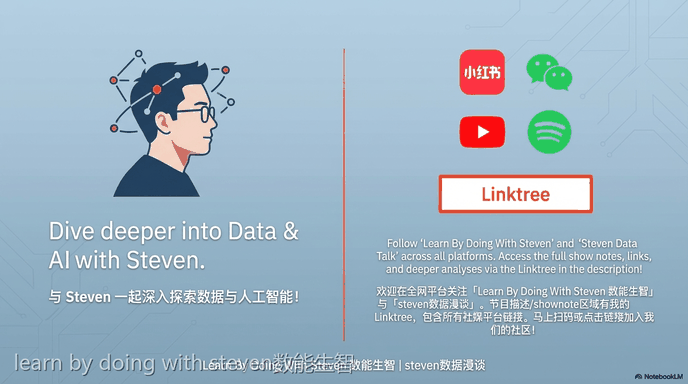
为了应对这些挑战,研究人员首先建立了一个统一的大语言模型增强的关系算子分类体系。该体系从操作逻辑、操作数粒度以及实现变体三个维度对现有算子进行了对齐与归类。具体而言,操作逻辑被划分为选择、匹配、插补、聚类和排序五种类型;操作数粒度涵盖了单元格、行、列和表格四个层级;实现变体则包括将所有元素打包进行一次性语言模型调用的策略,以及对每个元素进行逐一语言模型调用的策略等。
To address these challenges, researchers first established a unified taxonomy for large language model-enhanced relational operators. This taxonomy aligns and categorizes existing operators along three dimensions: operating logic, operand granularity, and implementation variant. Specifically, operating logics are classified into select, match, impute, cluster, and order; operand granularities cover cell, row, column, and table levels; and implementation variants include strategies such as using a batched model call for all elements, as well as calling the model for each element individually.
基于该分类体系,研究进一步设计了一个全面的评估基准平台。此基准平台横跨多个领域与不同结构的数据库,包含了大量的单算子查询和多算子查询测试用例。单算子查询测试覆盖了分类体系中所有的操作逻辑和操作数粒度组合,而多算子查询则根据查询的复杂程度进行了分层级设计,旨在为复杂的端到端语义查询系统提供具有高挑战性的实测任务。
Based on this taxonomy, the research further designed a comprehensive evaluation benchmark platform. Spanning multiple domains and structurally diverse databases, this benchmark includes a large volume of single-operator and multi-operator query test cases. The single-operator queries cover all combinations of operating logics and operand granularities in the taxonomy, while the multi-operator queries are stratified by complexity, aiming to provide highly challenging empirical tasks for complex end-to-end semantic query systems.
在针对单算子的评估中,研究分析了不同实现方式在有效性和可扩展性方面的表现,并得出了多项最佳实践指南。数据表明,在行级别的选择任务和列级别的插补任务中,逐一调用模型的策略表现出更强的准确性和稳健性。相反,对于匹配任务、聚类任务和排序任务,将所有候选数据打包进行一次性调用的全局视角策略通常能获得最佳性能,且有效降低了推理成本。此外,评估发现在一次性调用策略中,随着输入数据规模的扩大,模型会因为注意力分散而导致结构化生成能力崩溃,这表明系统设计必须在模型有限的有效上下文窗口与计算成本之间进行权衡。
In the evaluation of individual operators, the study analyzed the performance of different implementations in terms of effectiveness and scalability, deriving multiple best practice guidelines. Data indicates that for row-wise selection and column-wise imputation tasks, the element-wise calling strategy demonstrates stronger accuracy and robustness. Conversely, for match, cluster, and order tasks, the global-view strategy of batching all candidate data for a single call generally achieves optimal performance while effectively reducing inference costs. Additionally, the evaluation found that within the batched calling strategy, as the input data scale expands, the model suffers a breakdown in structured generation capacity due to attention dilution, indicating that system design must balance the limited effective context window of the model against computational costs.
该研究还对比了现有多算子系统与采用上述最佳实践配置的基准系统在端到端任务中的综合性能。测试结果显示,当前依赖大语言模型自动规划执行路径的多算子系统表现欠佳,难以有效应对复杂的查询任务,其错误往往源于初始规划阶段的失效。即便是一些依赖人工预设执行计划的现有系统,其任务准确率依然存在明显的提升空间。相较之下,采用本研究提出的经过验证的单算子最佳实践策略的组合系统,在不同的大语言模型底层支持下均持续取得了最优的综合表现,解决了相当比例的高难度复杂查询,证明了合理的算子设计和全面的功能支持对于系统性能具有决定性作用。
The study also compared the end-to-end performance of existing multi-operator systems against a baseline system adopting the aforementioned best practice configurations. Test results show that current multi-operator systems relying on automated language model planning perform poorly and struggle to effectively handle complex query tasks, with errors often stemming from failures in the initial planning stage. Even among existing systems that rely on manually preset execution plans, there remains obvious room for improvement in task accuracy. In contrast, the combined system utilizing the validated best practice strategies for single operators proposed in this study consistently achieved optimal overall performance across different underlying large language models, solving a significant proportion of highly difficult complex queries, which proves that rational operator design and comprehensive functional support play a decisive role in system performance.
基于完整的测试与分析,研究对关系型数据处理的未来发展方向进行了展望。在短期规划中,需要构建支持更全面算子集合、具备稳健规划功能,并能够实现经典操作与大模型调用联合优化的多算子系统。在长期愿景中,该领域将向以大语言模型为中心的数据库架构方向演进,不再将大语言模型仅视为外部调用的计算组件,而是围绕模型原生算子从底层重构数据库系统,最终实现多模态统一存储、语义感知检索以及自适应上下文管理等前沿特性的深度融合。
Based on the complete testing and analysis, the study outlined future development directions for relational data processing. In the short-term planning, there is a need to build multi-operator systems that support a more comprehensive set of operators, possess robust planning capabilities, and can achieve joint optimization of classical operations and model invocations. In the long-term vision, the field will evolve towards a large language model-centric database architecture, no longer treating large language models merely as external computational components, but rather rebuilding database systems from the ground up around model-native operators, ultimately achieving a deep integration of cutting-edge features such as multi-modal unified storage, semantic-aware retrieval, and adaptive context management.
感谢大家阅读本期内容的全面介绍。诚挚邀请各位观众与听众在各大平台关注Learn By Doing With Steven 数能生智频道,以及在YouTube Music、Spotify等各大主流播客平台上收听steven data talk和steven数据漫谈播客。我们在小红书、微信公众号、YouTube、Spotify等平台均同步发布相关深度内容。关于所有社交媒体平台的统一访问入口,请前往节目描述或shownote区域查看我的Linktree链接,期待大家的关注与交流。
Thank you all for reading this comprehensive introduction of our content. We sincerely invite our audience and listeners to follow the Learn By Doing With Steven YouTube channel across various platforms, and to tune into the steven data talk podcast on major podcast platforms like YouTube Music and Spotify. We concurrently publish related in-depth content on platforms including Xiaohongshu, WeChat Official Accounts, YouTube, and Spotify. For unified access to all our social media platforms, please check the Linktree URL located in the show notes or program description area. We look forward to your subscriptions and engagement.
https://arxiv.org/pdf/2603.02537
https://linktr.ee/learnbydoingwithsteven
#LargeLanguageModels #DatabaseManagement #DataScience #RelationalDatabases #ArtificialIntelligence #TechPodcast #StevenDataTalk #数能生智 #数据漫谈
